I’ve been asked to talk about content management and extensibility using vRSLCM at an upcoming customer event so as part of the preparation I decided to mock up some scenarios. This article will cover one of these scenarios and deals with content pipelines and extensibility.
What You Should Not Do
Before we dive into configuration I wanted to take a few minutes to cover some important topics around content pipelines. Alot of people are familiar with pipelines from CodeStream and have seen what you can do with them. The immediate assumption is that you can configure and use them in the same way within vRSLCM. This is NOT the case so lets look at some of things you should not do.
In the following screenshot there is an option to create a new pipeline. This option will almost certainly be disappearing in upcoming versions so to avoid locking yourself out of any custom pipelines in the future it is safer not to use them. Additionaly VMware does NOT currently support modifying any of the system pipelines (i.e. Content-Pipeline and multi_release_pipeline) despite allowing you to do so within the interface. Again, expect this ability to disappear in future versions.
Note: the stub pipelines (e.g. Content-Post-Capture) can be modified however you wish.

The second example covers how a pipeline can be used to call out to external systems. vRSLCM has 6 types of task operations that can be leveraged within a pipeline task (CodeSteam has many more e.g. Jira) however at the time of writing the preferred and recommended method (by the Cloud Management Business Unit within VMware) is by leveraging the “vRealize Orchestrator External” type. All of the other operations and more can be achieved from within an Orchestrator instance.

One of the main reasons for this recommendation is to help ensure upgrades can handle likely framework changes in future versions without impacting content.
To summarise, don’t edit the system pipelines (even though you physically can) and stick to leveraging an external vRO.
The Scenario
The scenario I am going to cover is calling out to a 3rd party system (in this case a WordPress site) to post notifications of content management operations (e.g. when a package has been captured).
To make this work I need to get a few things which are specific to WordPress. These include:
- Bearer Token for authentication
- API methods for performing operations against WordPress.com
Obtaining a bearer token requires me to define an application on the WordPress server within my account which generates an ID and client secret. I can use these (along with a time limited code) to obtain a bearer token using a separate API call to WordPress. Normally I would write a workflow to handle obtaining the code and exchanging the ID, secret and code for a bearer token however WordPress is setup for this being done by an intermediary application with redirect URLs. The code needed for the exchange is appended to the redirection URL.
As the bearer token is not time limited I have elected to just use a web browser to get the code and POSTMAN to do the exchange. I can then store the bearer within Orchestrator and call it as and when needed.
Configuring an External vRealize Orchestrator Server
Before you can do anything with an external Orchestrator server and pipelines, vRSLCM needs to be configured to connect to a “pipeline_vro” endpoint. This is done by editing the following file:
opt/vmware/vlcm/blackstone/configuration/vrcs-config/endpoints/system-vro.json
The connection details need to be replaced in the pipeline_vro section (server name, username and password) which will look like the following
name”: “pipeline-vro”, “description”: “Pipeline VRO Server used by Content Lifecycle Management Services”, “type”: “vrcs.vco:VCOServer”, “properties”: {“url”: “https://@LOCALHOST@:8281”, “username”: “@VRO_USER@”,”password”: “@VRO_PASSWORD@”,”ignoreCertificateCheck”: “yes” }, “tags”: [], “tenantLinks”: [ “/tenants/default/groups/default”,”/tenants/default” ]
Note: that the password is currently stored as clear text so think about that before you hook up a production Orchestrator server:
Tagging a Workflow
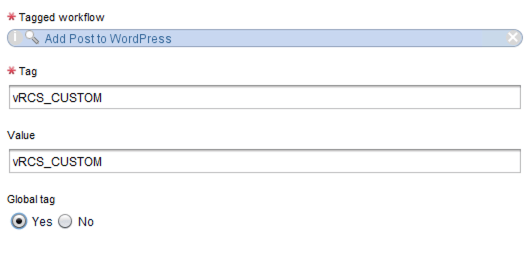
vRSLCM identifies workflows that can be called by content management pipelines by looking for a workflows that are tagged with a specific Orchestrator tag. To tag a workflow you can simply run the out of the box “Tag Workflow” workflow. The tag and value must be “vRCS_CUSTOM” (it is case sensitive so make sure the letter v is lowercase).
Editing a Pipeline Stub
As I stated earlier, modifying a system pipeline is not supported however the pipeline stubs can be modified however you wish. For this scenario I am going to modify the “Content-Post-Capture” stub which out of the box just fetches content from http://www.vmware.com. This stub will run every time a package has been captured by the content management engine (once we turn it on).
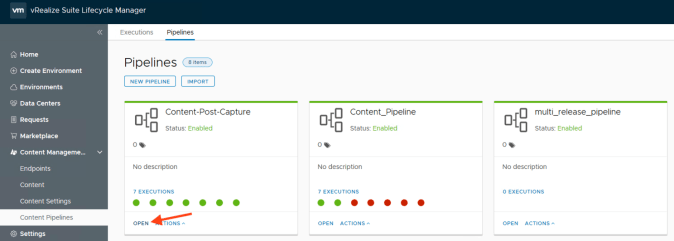
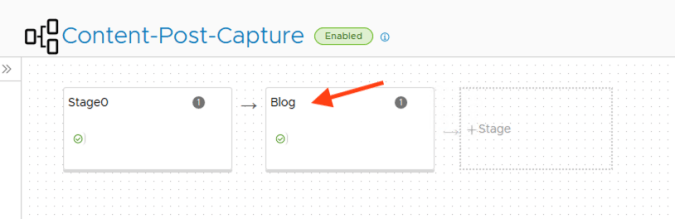
Here I have added a new stage called “Blog” and a new task within the stage called “Add Blog Post”.

My workflow takes a number of inputs from vRSLCM including the name of the pipeline stub, package version, package name and package type. These are all pre-defined inputs that come with vRSLCM and are fed by the content management engine.
Note: If you type $ into an input field and select “input” then a list of available fields will be shown for you to choose from.
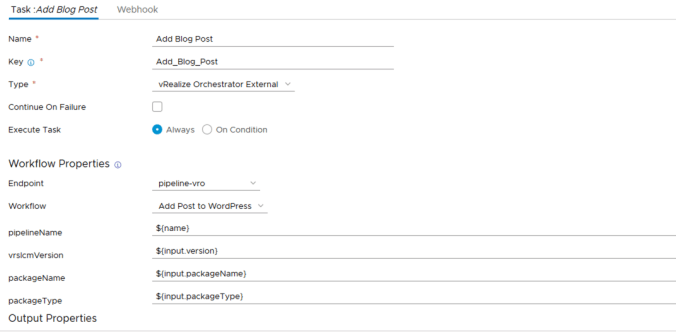
Once you are happy with the modifications you can save the stub pipeline.
The final action is to enable the stub pipeline.
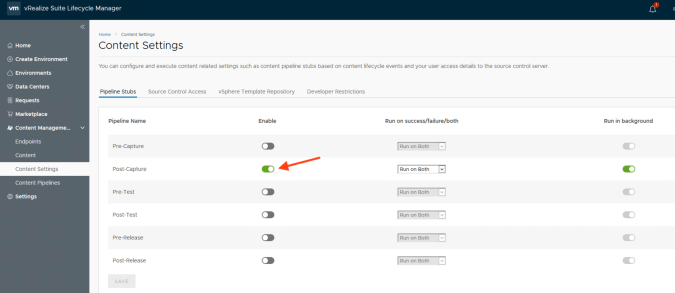
Capturing Content
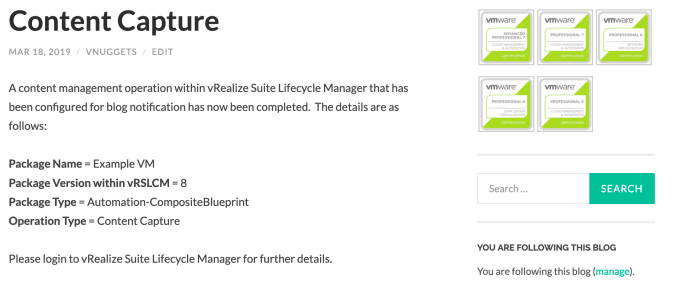
Now when I capture content my workflow runs.

The blog post is titled based on what type of stub pipeline was used and formatted based on the html code passed by my workflow to WordPress.
The Workflow Code
For anybody who is interested, my workflow code is as follows:
switch(true)
{
case (pipelineName.toLowerCase().indexOf("capture") != -1):
operationType = "Content Capture";
break;
case (pipelineName.toLowerCase().indexOf("test") != -1):
operationType = "Content Test";
break;
case (pipelineName.toLowerCase().indexOf("release") != -1):
operationType = "Content Release";
break;
default:
operationType = "vRSLCM";
}
//Build message contents in urlencoded format (needed for wordpress)
var content = "content=A content management operation within vRealize Suite Lifecycle Manager that has been configured for blog notification "
+ "has now been completed. The details are as follows:<br><br>"
+ "Package Name = " + packageName + "<br>"
+ "Package Version within vRSLCM = " + vrslcmVersion + "<br>"
+ "Package Type = " + packageType + "<br>"
+ "Operation Type = " + operationType + "<br>"
+ "Please login to vRealize Suite Lifecycle Manager for further details."
var categories = "categories=Demo vRSLCM Content Posts";
var payload = "title=" + operationType + "&" + content + "&" + categories;
//Create Rest Request
var request = restHost.createRequest("POST", "/rest/v1.1/sites/vnuggets.com/posts/new?pretty=true", payload);
request.contentType = "application/x-www-form-urlencoded";
request.setHeader("Authorization", "Bearer xxxxxxxxxxxxxxxxxxxxxx");
//Execute Rest Request
var response = request.execute();
System.log(response.contentAsString);
