If you have been following my Ansible articles (https://vnuggets.com/category/3rd-party-solutions/ansible/) that covers getting up and running then you should be comfortable with the process of building a Playbook to apply configuration to an existing machine.
In this article we are going to look at bringing Ansible and VMware Cloud Assembly together to provide a way to provision machines and automatically configure them using Cloud Assembly.
Defining the Integration
Before we can do anything with Ansible we first have to get an Ansible endpoint configured within Cloud Assembly (known as an “integration”).
In this example I am using an Ansible setup on an on-premise CentOS 7 server therefore the location is set to “Private Cloud” and my communications will leverage a cloud proxy appliance within my private cloud.
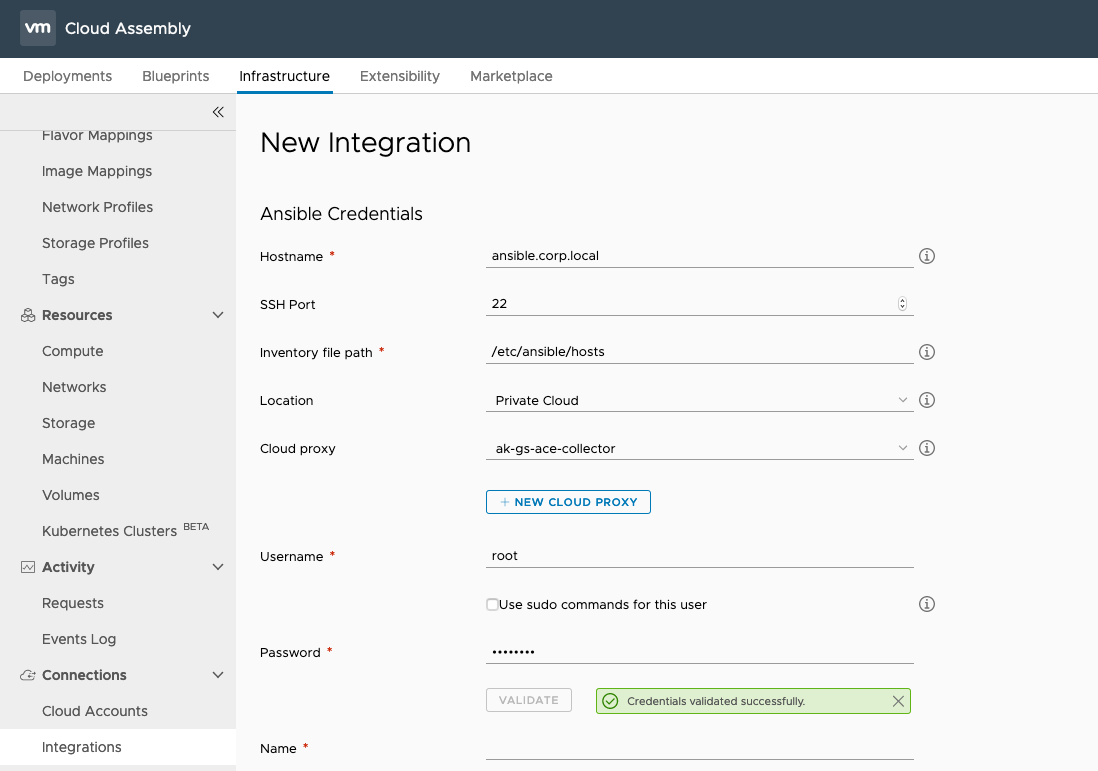
For this test setup i am using the root account to connect to the Ansible host however in most scenarios you will most likely be using a non-root account combined with sudo.
If you have installed Ansible to a directory other than the default /etc/ansible or if the hosts file has been moved to another location then the Inventory path should be updated to match. This is because Cloud Assembly reads and manipulates the inventory file upon provisioning and de-provisioning in the same way that an Ansible administrator would when adding and removing client machines.
Blueprints with Ansible
To configure a blueprint to use Ansible as part of its provisioning process the Ansible component must be added to the canvas via drag and drop (you can of course just copy and paste yaml to the bluerprint yaml specification if you already have it).
In this example we are going to start with a base blueprint that is setup for using an existing network which provisions a CentOS 7 VM from a template image.

When the Ansible object is dropped onto the canvas the yaml skeleton configuration is added.

At this point there is no link between the VM component and the Ansible configuration so the first thing that needs to be done is to create that relationship. This is as simple as drawing a line between the 2 components which updates the Ansible component with the information from the VM component.
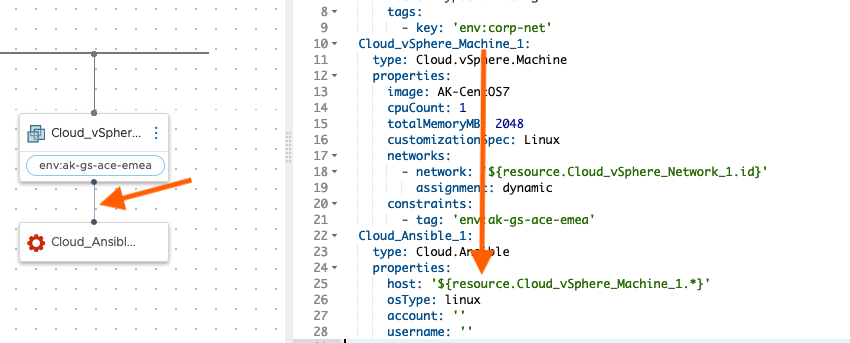
The ‘host’ attribute is used to send the name (this actually means IP address) of the VM being deployed to Ansible so that it can be added to the ‘hosts’ inventory file on the Ansible server (note you can specify an alternative inventory file using an Ansible property in the blueprint yaml).
Now that the initial link is complete there are some other pieces of information that need to be added to the Ansible yaml in the blueprint in order to make things work.
The first three pieces to add are:
- “account” – the name of the integration that was added to Cloud Assembly at the start of this article
- “username” – defines the user that Ansible will use when it connects via SSH to the VM that will be deployed via this blueprint
- “privateKeyFile” – the private SSH key that corresponds to the public key I have added to my CentOS 7 template image
If you have been following my previous Ansible articles you will know that my CentOS template is already configured with a local user called “admin” and the image has a public SSH key in “authorized_keys” under the admin user.

The next set of info required is:
- “groups” – the names of the Ansible groups we want the machine being provisioned to be placed into within the inventory file (hosts by default)
- “playbooks” – the full paths to the Ansible playbooks that should be executed (further classified by using provision or de-provision attributes to handle different playbooks to be run during the VMs lifecycle)
As both of these attributes take arrays as inputs we can provide multiple entries for each if required by adding a new line under the heading for each additional entry required.

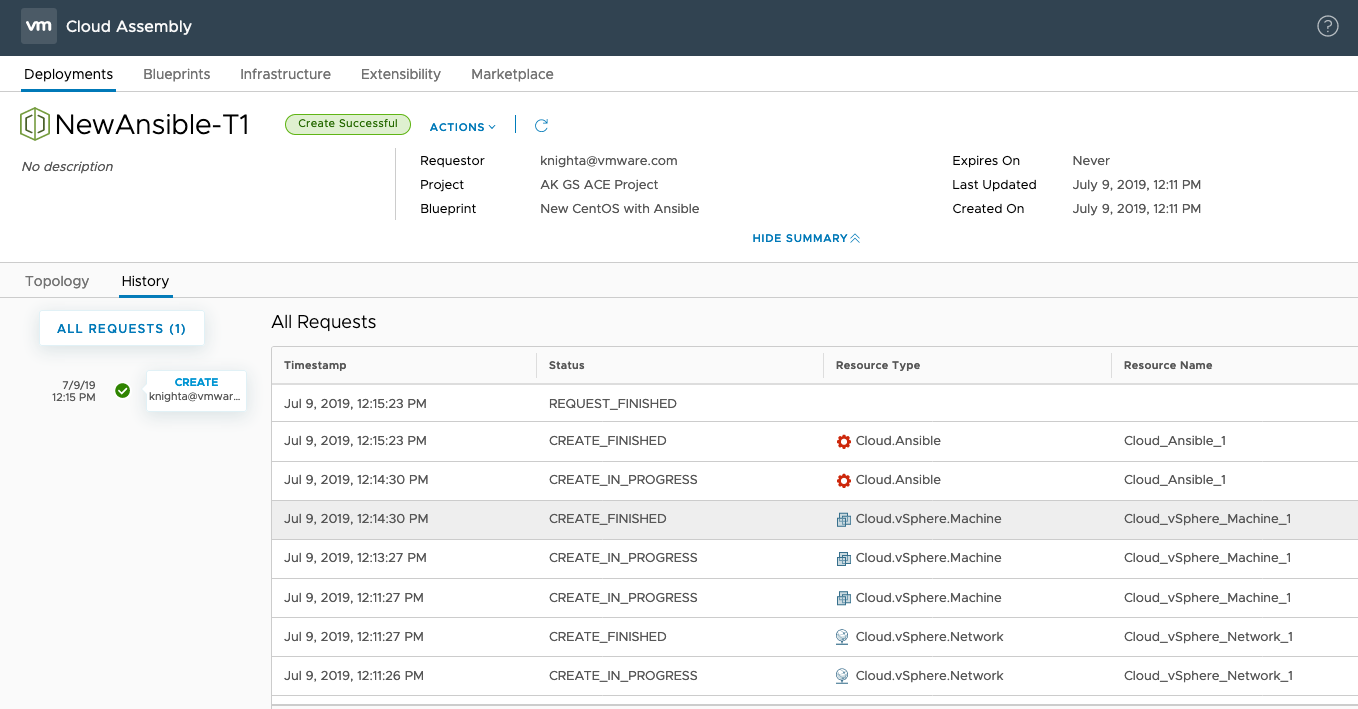
The blueprint when deployed will now build a machine based on our CentOS 7 template image (customized with a vSphere customization spec for IP assignment and hostname application) and then run the configuration within the “centos.yml” playbook.
The deployment history shows the Ansible configuration was applied successfully.
Note: If you configure a blueprint and don’t include a Playbook setting then Ansible will still put the VM into the inventory file (default hosts file unless overridden) but it won’t apply any configuration on the VM.
The Playbook I am using deploys Apache with some basic configuration including firewall changes and a single string of text in a index.html file. Once a test machine is deployed then we should be able to access the Apache web server and see the customized text on the default web page.
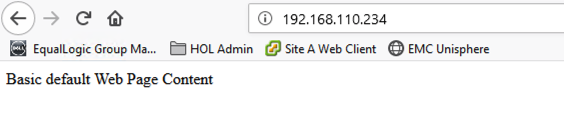
User Selections for Ansible Configuration
The blueprint currently is static in nature so any requestor will always get the same configuration that is applied by Ansible and nothing else. To make the blueprint more dynamic in nature I am going to show you how to add more configuration.
The first thing we want to do is offer the requestor the choice of what type of deployment this will be. The idea here is that based on this selection we can drive different configurations to be applied to the VM produced.
Our input will be called “ServerGroups”. I could set it up to only offer a text field for the requestor to type their group names into however in this case we want to control the selections so I am using “items” and “enum” to pre-define the options.
As a machine can be a member of more than one Ansible server group AND the Ansible attribute “groups” takes an array as a value, “ServerGroups” is defined as an array of strings which will allow a requestor to select one or more of the defined server group names. This gives us the following input section for the blueprint.

Attaching Group Selections to Ansible
Now that the requestor has an option to select one or more server groups we need to attach that selection to the Ansible configuration within the blueprint. Our static configuration is changed from this:
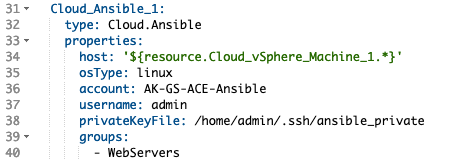
to this:
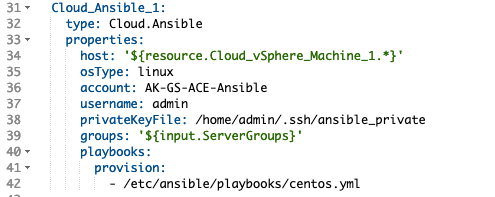
Now when requesting a deployment via this blueprint the user gets the following options.
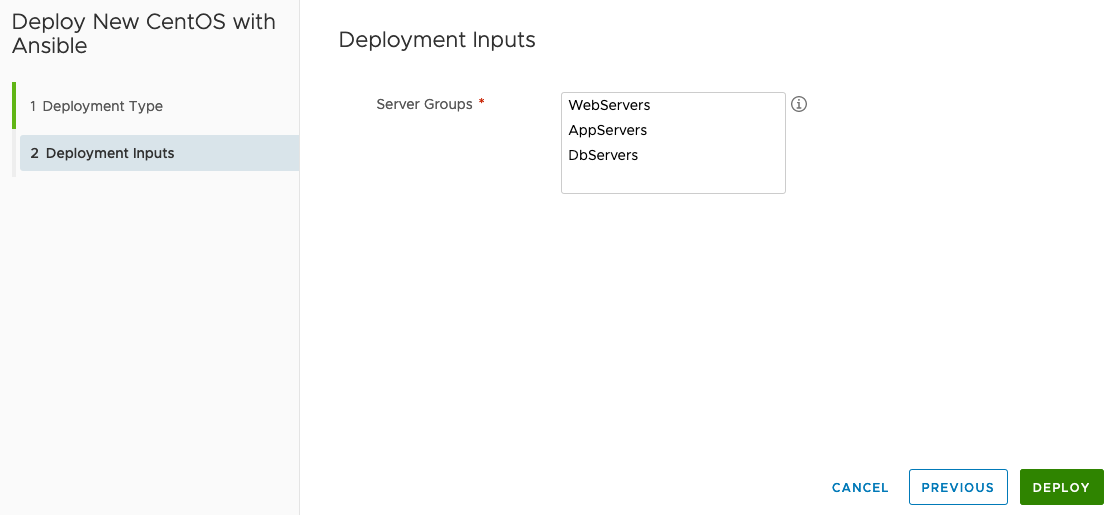
As the input is an array the requestor can select one or more groups by highlighting (i.e. clicking on) those options that are required.

Note: To make multiple group selections work with a single playbook you need to create a different play (or set of plays) for each server group.
