In this article I am going to take the information from the previous articles in this series and use it to build my use case using ABX.
Links to the previous 2 articles in this series can be found via the links below.
Python or Node.js
FaaS providers generally support a number of run-time environments that functions can be written to use with each run-time using a specific language. With Cloud Assembly this run-time list shrinks to 2 for ABX actions, Python and Node.js.
There are a number of factors that come into play when selecting which run-time to use including:
- previous experience
- language familiarity (i.e. if the run-time is written in a language that you are familiar with)
- synchronous vs asynchronous requirements
- supported modules
I do most of my scripting in JavaScript. It is the language I am most familiar with and I have been creating vRealize Orchestrator code for 10+ years which is also based on JavaScript. Conversely I have not much experience with the Python language, so knowing that Node.js uses JavaScript it might make sense to leverage Node.js.
The key factor here though is that Node.js uses asynchronous calls for everything, requiring extensive use of callbacks to fetch results from various commands. To me this over-complicates what I am trying to achieve. Python on the other hand uses the same object orientated approach to JavaScript just with subtly different commands and syntax so it’s Python I am going to use (who doesn’t love learning something new!).
w3schools has some useful code snippets to get you started if you are unfamiliar with Python (https://www.w3schools.com/python/python_intro.asp).
Inputs, Functions, Dependencies and Providers
There are several fields within an ABX action that need to be populated to make the action work. These include:
- Main Function – the name of the function the action will execute when the action is called
- Inputs – any specific inputs that you want to add to the action together with their values (these can then be leverage within the action code you write)
- Dependency – Any run-time specific modules that are required for your code to work (the modules will be loaded when the action runs)
- FaaS Provider – whether you when to auto-select a specific FaaS provider or fix the action to one
These inputs look like this. Here I am using the default function name, no additional inputs, a dependency on the “requests” Python module (more about this later) and specifically setting this action to be used with an on-premise FaaS Provider (i.e. VMware Extensibility Appliance).
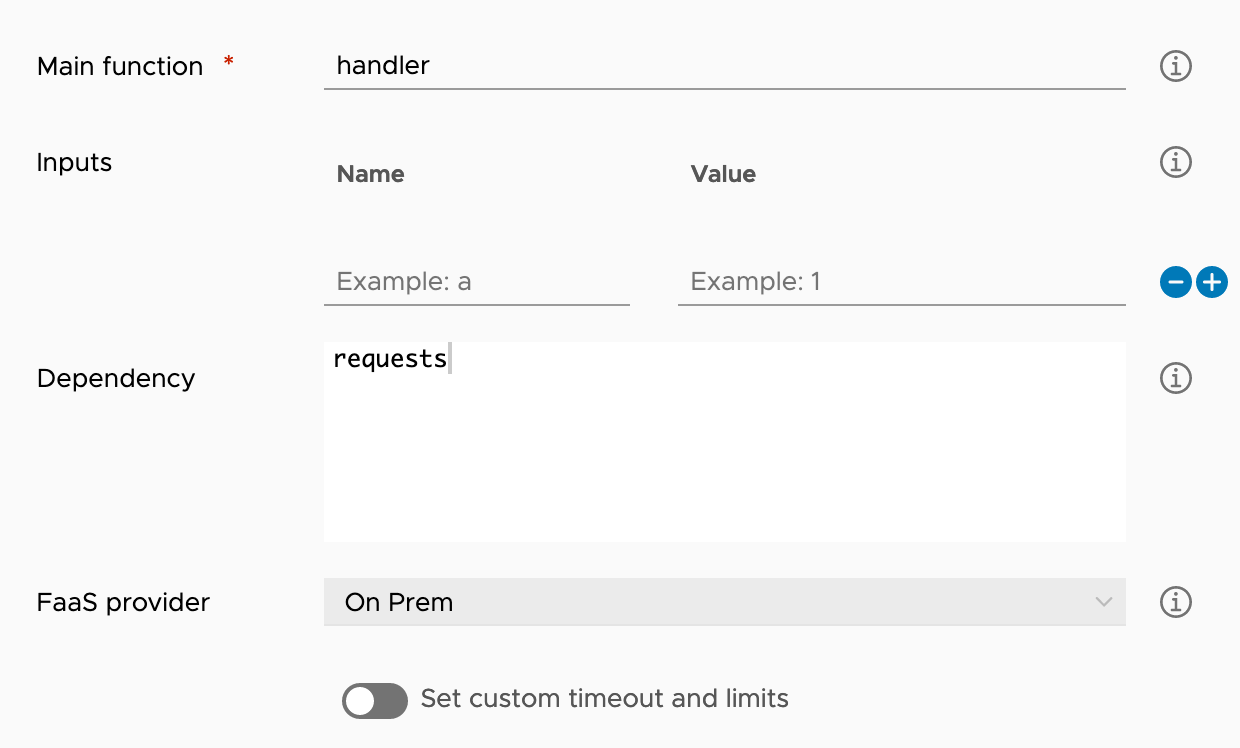
The action will automatically receive the event payload so I can make use of any of the information within the payload when writing the Python code.
Passing Information Between Actions
When executing multiple actions as a “flow” (a sequence of actions executed for the same event) you will probably need to pass information obtained in one action to another. An example of this would be for authentication. If you obtain an API key in one action and other actions need to use that key then you need to pass that key to the other actions.
With ABX actions, any output you create will automatically be available as an input for all other actions in the same flow. Here’s an example:
#Action 1
outputs = {}
outputs['apiToken'] = 1234567890
return outputs
#Action 2
auth = inputs['apiToken']
The “return” in Action1 passes the “outputs” object back to the event handler and in the case of a flow execution makes it available within “inputs” for Action2 (or any other action in the flow).
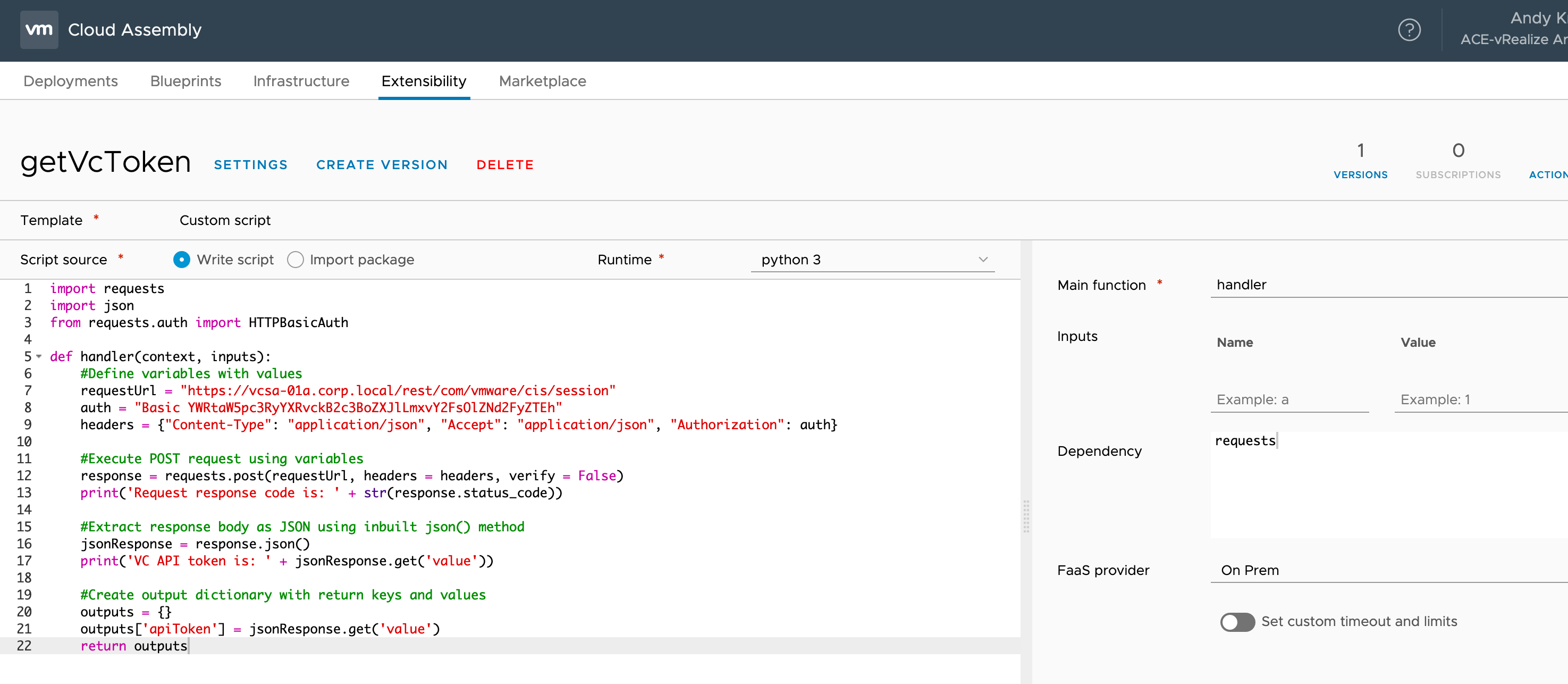
Getting a vCenter API Session Key
My first action is to get an API session key to use for authentication with all the other functions. This requires me to use the “requests” Python module to create and execute a HTTP/S request and the “json” module for handling the request output (i.e. extracting values via key names).
I have added my users password to the code in base64 encoded format however for production use you might consider other options such as reading a password in from the user at request time and then extracting it from the event payload before converting it to base64.
import requests
import json
def handler(context, inputs):
#Define variables with values
requestUrl = "https://vcsa-01a.corp.local/rest/com/vmware/cis/session"
auth = "Basic YWRtaW5pc3RyYXRvckB2c3BoZXJlLmxvY2FsOlZNd2FyZTEh"
headers = {"Content-Type": "application/json", "Accept": "application/json", "Authorization": auth}
#Execute POST request using variables
response = requests.post(requestUrl, headers = headers, verify = False)
print('Request response code is: ' + str(response.status_code))
#Extract response body as JSON using inbuilt json() method
jsonResponse = response.json()
print('VC API token is: ' + jsonResponse.get('value'))
#Create output dictionary with return keys and values
outputs = {}
outputs['apiToken'] = jsonResponse.get('value')
return outputs
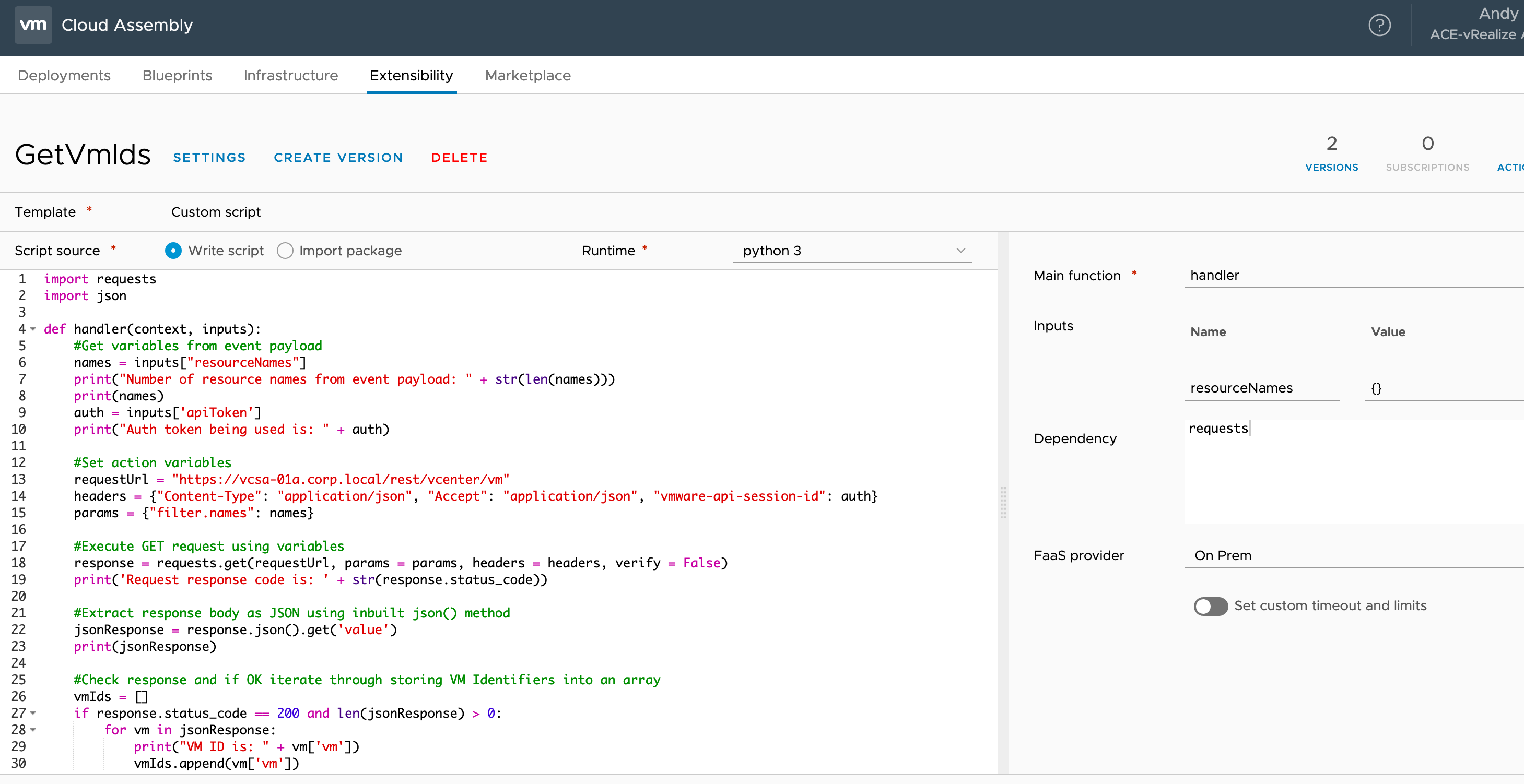
Get Virtual Machine Identifiers
The second action fetches the virtual machine identifier values in the payload so that they can be used for assigning tags later on. This requires authentication using the API session key so I am using the output of the first action and reading that in as an input to this action.
The product of this action is also output in the same way.
import requests
import json
def handler(context, inputs):
#Get variables from event payload
names = inputs["resourceNames"]
print("Number of resource names from event payload: " + str(len(names)))
print(names)
auth = inputs['apiToken']
print("Auth token being used is: " + auth)
#Set action variables
requestUrl = "https://vcsa-01a.corp.local/rest/vcenter/vm"
headers = {"Content-Type": "application/json", "Accept": "application/json", "vmware-api-session-id": auth}
params = {"filter.names": names}
#Execute GET request using variables
response = requests.get(requestUrl, params = params, headers = headers, verify = False)
print('Request response code is: ' + str(response.status_code))
#Extract response body as JSON using inbuilt json() method
jsonResponse = response.json().get('value')
print(jsonResponse)
#Check response and if OK iterate through storing VM Identifiers into an array
vmIds = []
if response.status_code == 200 and len(jsonResponse) > 0:
for vm in jsonResponse:
print("VM ID is: " + vm['vm'])
vmIds.append(vm['vm'])
else:
raise ValueError("Response code was not 200 or no matching results found")
#Create output dictionary with return keys and values
outputs = {}
outputs['vmIds'] = vmIds
return outputs
Note that the following screenshot has an empty “resourceNames” input defined. This is to allow me to test the action in isolation otherwise without an event payload the code would fail due to the key name not being found in the event payload.
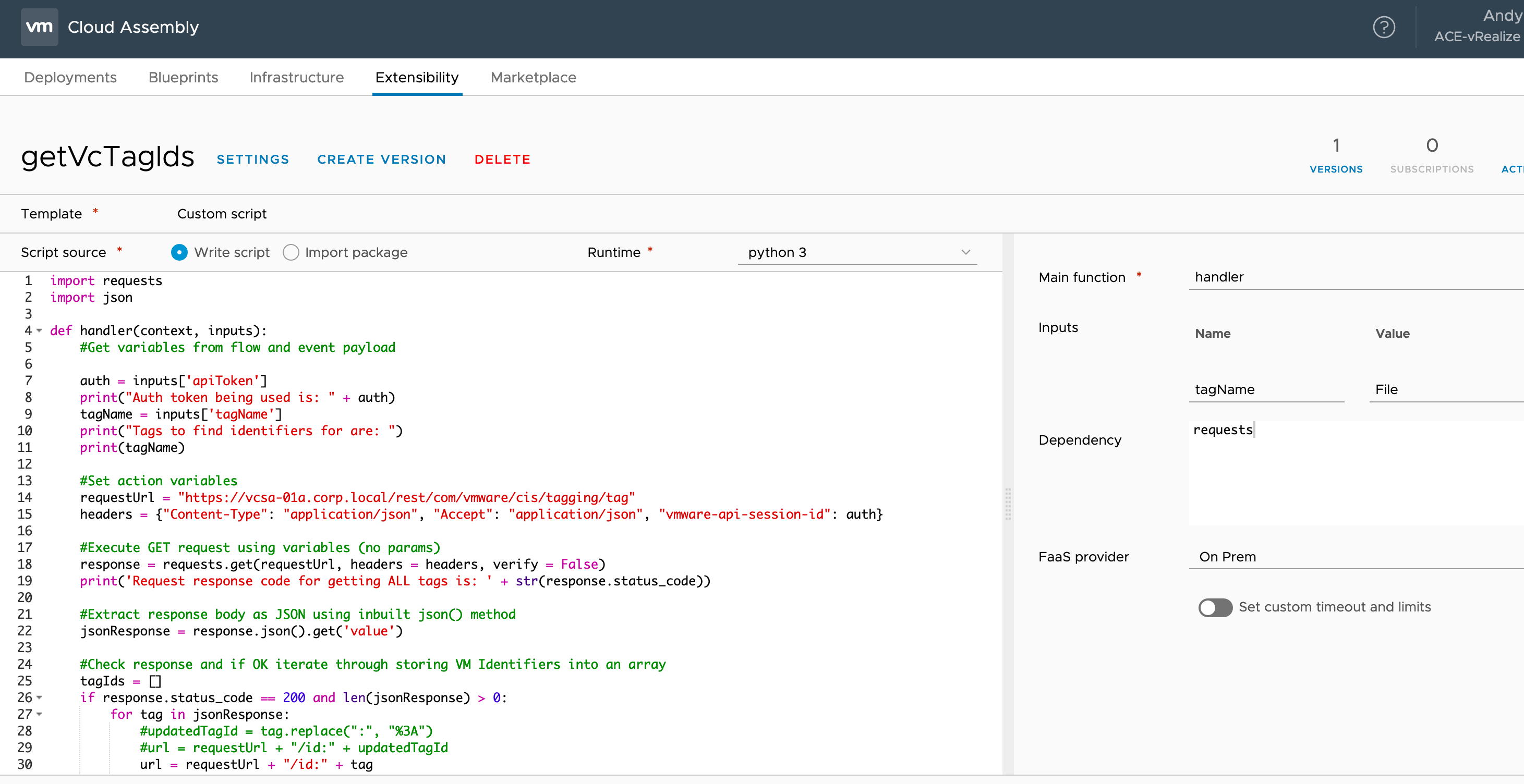
Get Tag Identifiers
This action does the same thing as the previous action except that it does it for tags rather than virtual machines.
import requests
import json
def handler(context, inputs):
#Get variables from flow and event payload
auth = inputs['apiToken']
print("Auth token being used is: " + auth)
tagName = inputs['tagName']
print("Tags to find identifiers for are: ")
print(tagName)
#Set action variables
requestUrl = "https://vcsa-01a.corp.local/rest/com/vmware/cis/tagging/tag"
headers = {"Content-Type": "application/json", "Accept": "application/json", "vmware-api-session-id": auth}
#Execute GET request using variables (no params)
response = requests.get(requestUrl, headers = headers, verify = False)
print('Request response code for getting ALL tags is: ' + str(response.status_code))
#Extract response body as JSON using inbuilt json() method
jsonResponse = response.json().get('value')
#Check response and if OK iterate through storing VM Identifiers into an array
tagIds = []
if response.status_code == 200 and len(jsonResponse) > 0:
for tag in jsonResponse:
#updatedTagId = tag.replace(":", "%3A")
#url = requestUrl + "/id:" + updatedTagId
url = requestUrl + "/id:" + tag
print("Fetching tag name for ID " + tag + " with URL " + url)
response = requests.get(url, headers = headers, verify = False)
print("Response code for tag fetch is: " + str(response.status_code))
jsonResponse = response.json().get('value')
if response.status_code == 200 and len(jsonResponse) > 0:
if jsonResponse['name'] == tagName:
print("Storing tag ID for matched tag name")
tagIds.append(jsonResponse['id'])
else:
raise ValueError("Response code was not 200 or no tag returned for ID")
else:
raise ValueError("Response code was not 200 or no tags found")
#Create output dictionary with return keys and values
outputs = {}
outputs['tagIds'] = tagIds
return outputs
In this case you can see that I have hard coded an input for the action “tagName” with a value of “File”. In other words I have statically set the tag I want apply to any virtual machine this action is executed for. In a production environment you may want to adjust this and offer that tag as a user selectable option in the blueprint.
Associate Tags to Virtual Machines
My last action is to use the identifiers that have been located in the previous 2 actions to associate the tag with the virtual machines. To do this a payload body needs to be formed in the Python code which contains all the necessary information required to make the association. Then for each virtual machine the code POSTs the payload via the appropriate REST API call.
import requests
import json
def handler(context, inputs):
#Get variables from event payload
vmIds = inputs["vmIds"]
print("Number of VMs to attach tags to: " + str(len(vmIds)))
tagIds = inputs["tagIds"]
print("Number of tags to apply: " + str(len(tagIds)))
auth = inputs['apiToken']
print("Auth token being used is: " + auth)
#Set action variables
requestUrl = "https://vcsa-01a.corp.local/rest/com/vmware/cis/tagging/tag-association"
headers = {"Content-Type": "application/json", "Accept": "application/json", "vmware-api-session-id": auth}
params = {"~action": "attach-multiple-tags-to-object"}
body = {}
body['tag_ids'] = tagIds
body['object_id'] = {}
body['object_id']['type'] = "VirtualMachine"
#Execute POST request using variables
for vm in vmIds:
body['object_id']['id'] = vm
print("tagging VM with ID: " + vm)
response = requests.post(requestUrl, params = params, headers = headers, data = json.dumps(body), verify = False)
print('Request to tag VM response code is: ' + str(response.status_code))
#Extract response body as JSON using inbuilt json() method
jsonResponse = response.json().get('value')
print(jsonResponse)

Flows, Forks and Joins
Now that I have the necessary actions created I need to link them all together so that they can be executed in the right order. Note that it is possible to put all of the code into a single action however this generally makes the action large and harder to understand and follow.
A flow can execute actions in series (i.e. one after the other) or in parallel (multiple actions together). Moving between series and parallel and vice versa executions requires “forks” and “joins”.
The way you construct the flow will depend on whether you need information from one action before you can execute another (i.e. dependencies).
In my scenario I have the following dependencies.
- getVcToken – has to be executed first as nothing can be done without authentication
- getVmIds – dependent on getVcToken
- getVcTagIds – dependent on getVcToken
- associateTagsToVms – dependent on getVmIds AND getVcTagIds
The dependencies mean that “getVmIds” and “getVcTagIds” can be executed at the same time (both not before getVcToken has been executed) however the output of both are required before “associateTagsToVms” can be executed. This translates to a “fork” and “join” being required in the flow.
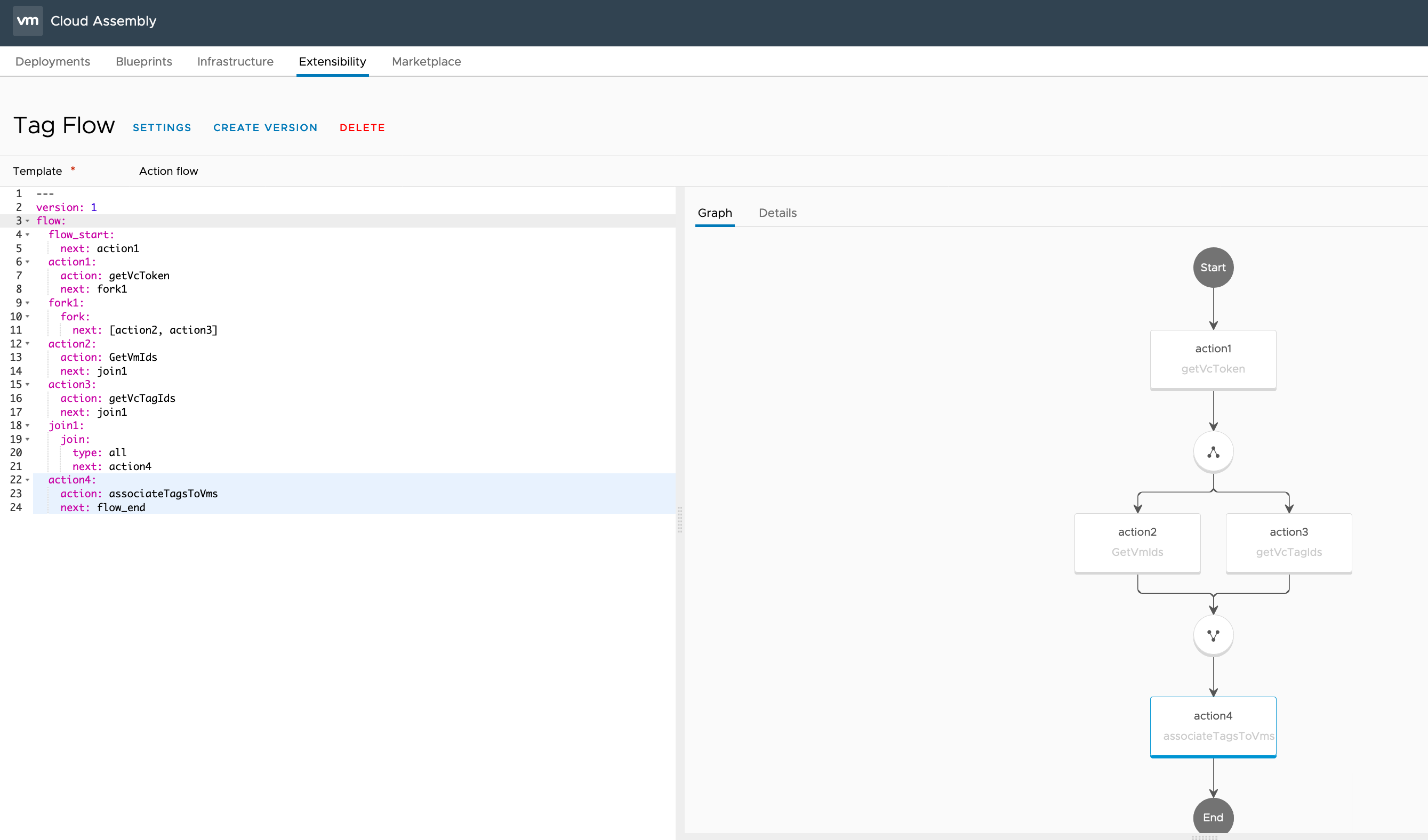
The code of the flow is as follows:
---
version: 1
flow:
flow_start:
next: action1
action1:
action: getVcToken
next: fork1
fork1:
fork:
next: [action2, action3]
action2:
action: GetVmIds
next: join1
action3:
action: getVcTagIds
next: join1
join1:
join:
type: all
next: action4
action4:
action: associateTagsToVms
next: flow_end
This is translated to a visual representation of the execution ordering in the following screenshot. You can see that after the first action is executed the flow forks to allows multiple actions to be executed at the same time before bring the flow back together to execute the final action.
Creating the Subscription
Once the flow has been saved the final task is to define the subscription which tells Cloud Assembly the action/flow to execute and under what circumstances.
Here I have selected the “Compute Post Provision” event as the event topic and the runnable item as the “Tag Flow” that I have just created. In my use case there is no requirement for making this a “blocking” subscription (i.e. preventing anything else from happening on a VM until the subscription has been executed) but I have restricted the subscription so it’s only relevant for my deployments.

Finally a deployment can be performed and the action runs witnessed.
Conclusion
ABX is not as daunting as it might first seem. The same logic and overall methodology can be used to implement vRO and ABX based extensibility so the method you select may come down to personal preference or be based on the type of cloud you are using.

Pingback: Cloud Assembly – Extensibility with ABX (FaaS) – Part2 | vnuggets
Pingback: Cloud Assembly – Extensibility with ABX (FaaS) – Part1 | vnuggets