Overview
vRealize Operations 8.0 is about to go to GA (at the time of writing) and there are some changes with regards to the overall deployment architecture that can be used so now is a good time to start looking at how you may want to deploy this new version within your environment. Let’s dive in!
What Changed?
Through many version of vROps up to (and including) vROps 7.5 there have always been two main types of deployment architectures for a cluster (plus the options of remote data collectors). These are:
- vROps cluster without application HA
- vROps cluster with application HA
With 8.0 things have changed somewhat or should I say the options have increased by 1. We now have the capability to use a CA (Continuous Availability) architecture which allows you to spread a single vROps cluster across multiple sites/data centers/fault domains without the requirement of stretched layer 2 networks or VXLAN/Geneve multi-site networks. Things are about to get interesting!
Example Deployment Architecture
Lets look at how this might be used. Firstly to use Continuous Availability the number of data nodes within the cluster must be an even number for reasons that will become clear shortly. So if you have a Master node and 2 data nodes you would need to add a 3rd data node to make things even. Easy so far!
But how do we maintain data availability when there is no sign of a replica node you may be asking. Well, quite simply enabling CA automatically enables the use of a replica node to ensure that the clusters data is in 2 separate places (i.e. Master and Replica need to be in separate fault domains). Now we have a deployment that looks as follows.
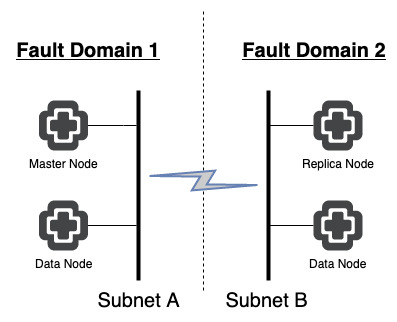
However, if communications are lost between sites/fault domains what happens? Well now comes the new stuff. You need an appliance that is designated as a witness node. That’s right, we need a node majority for this to function correctly. The witness node does not take part in any data analytics or store any metric data. The only purpose of this node is to decide which half of a vROps cluster should remain active if the communications between each half of the cluster is lost.
The witness node needs to be located in a 3rd location which would not be affected by the loss of either fault domain 1 or 2. This is to ensure that if either becomes unavailable the witness node will provide node majority to allow the cluster to continue functioning.

What Happens During Failure?
This part of the system has not changed. If in our example “Fault Domain 1” were to go offline or fail, fault domain 2 and the witness node would provide the node majority of the cluster leaving the replica node in “Fault Domain 2” functioning as the new Master node and the cluster running in a degraded state.

Correcting the issue with “Fault Domain 1” would result in the original Master node coming back as the new Replica node, returning the cluster to a healthy state.
Should “Fault Domain 1” not be recoverable then the old Master node could be explicitly removed from the cluster and new nodes created to add back to the cluster enabling a new Replica to be specified.
I’ll be covering more new features in the coming weeks so stay tuned!
