One of the core functions within a monitoring and optimisation solution is to detect when something is not normal and to then do something about it. In this example we have requirement for a specific host cluster to alert based on lower thresholds for CPU Workload %.
Symptom Definitions
A Symptom Definition allows the administrator to describe a situation that is NOT normal within a given environment. vROPs comes pre-configured with many symptom definitions that are set to values which are a good starting point for “most” environments.
The definitions highlighted below relate to our metric at the start of this blog post. Here you can see this metric has 3 definitions, each one relating to a different severity level.
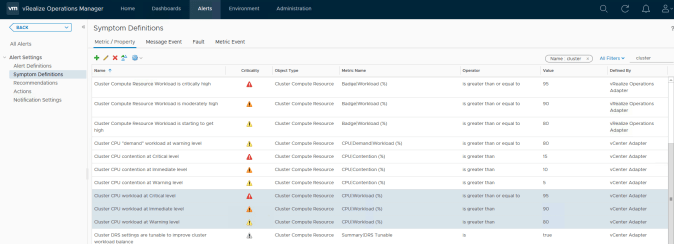
As we don’t want to lower our thresholds for all clusters we will create 3 new Symptom Definitions. To do this you can select each definition and use the clone button on the toolbar to copy it and modify the values on the copy. We will prefix the name of each one with “DEMO” so they are easy to locate.
Using the filter option we can search for our new definitions using “DEMO” as the search parameter. Here they are with the adjusted thresholds.

Alert Definitions
The Alert Definition tells vROPs which symptoms to use to gauge when to issue an alert. For our use case an Alert Definition already exists for cluster CPU workload however this is configured with the default cluster CPU workload symptom definitions and therefore the incorrect thresholds.

We can either clone this existing Alert Definition and modify its values or we can create a brand new Alert Definition. In this example we will clone the existing and modify it. As with the Symptom Definition, the name has been prefixed with “DEMO” to make it easier for us to find the Alert Definition when finished.
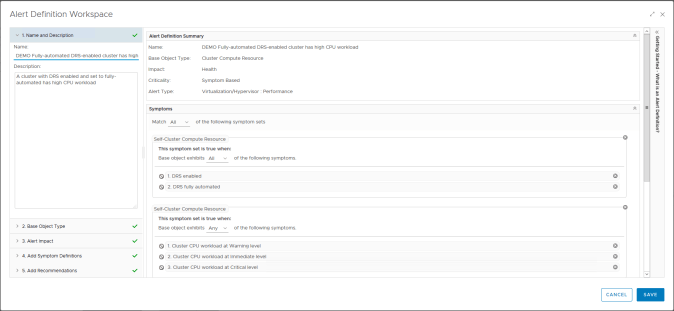
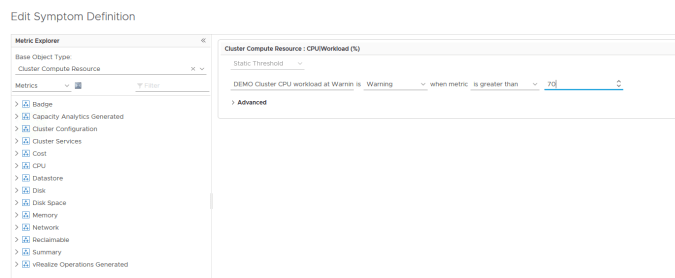
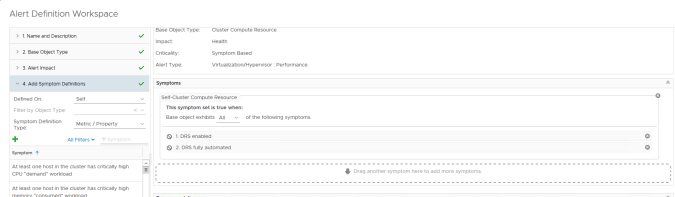
We do not need to modify the base object type, impact, criticality or alert type as we are using a cloned Definition and therefore these values should be correct. If we want to adjust the sensitivity of the alert then you could adjust the number of wait cycles and cancel cycles at this point. Increasing this numbers means that the alert would not be triggered until the condition had been seen for X success times and would not cancel until the alert was no longer seen for X successive times.

In this example the Alert Definition is specifically for fully automated DRS clusters as denoted by this symptom. We won’t change this as our specific cluster is also DRS enabled.
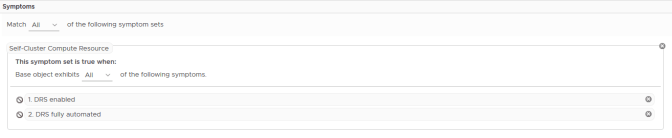
The second set of symptoms is where we will make our changes. These are the default symptoms and will need to be deleted before our DEMO symptoms are added back in.
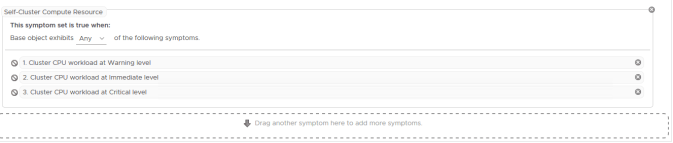
We can delete the old symptoms by using the delete button at the end of each symptom or by using the delete button on the whole symptom set. As we don;t need any of them we will delete the set. Our definition now looks like this:
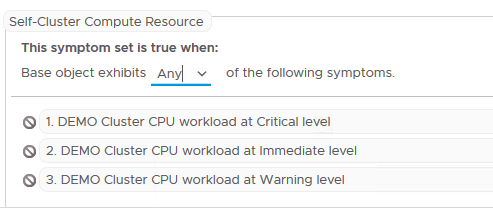
We will now add our new DEMO symptoms back to the alert definition by searching for them using the filter option.

Once we have found them each can be dragged onto the symptoms pane as shown below.

There is one more configuration change we now need to make and that is to adjust the alert condition for our DEMO symptoms. By default vROPs has decided that all of our symptoms must be true before the alert will be flagged. This is not what we want. We need to adjust this so that if ANY of the symptoms are seen the alert is then flagged.
The Alert Recommendations can stay the same unless there is something specific the administrator of our DEMO cluster need to do. Our DEMO Alert Definition can now be saved and should be visible.

Our Alert Definition can now be added to a policy which covers our DEMO cluster and the default 3 Alert Definitions removed. We will cover this in a further blog post.
Notifications
Our new Alert Definition is now active (assuming it has been applied to the DEMO cluster by the appropriate policy) and this should flag alerts within the vROPs cluster when the various thresholds are crossed.
We may want specific users to be alerted outside of the vROPs platform and to do this we need to set up a “Notification Setting” rule.

We will create a rule called “DEMO Cluster” which will use email alerts via the Standard Email Plugin. I assume that an SMTP host has already been added to vROPs.

Our rule can be configured in multiple ways using various filters. The scope of the rule determines whether we want to send emails for alerts on a specific object, for a type of object or based on tags etc.
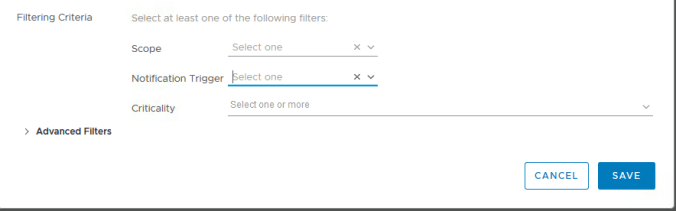
In our use case we just want to send email alerts for a specific cluster so our scope will be “Object” and then we can choose our cluster by searching for its name.

Our “Notification Trigger” could be either based on Alert Type, Impact or a specific Alert Definition. If this rule is going to cover email alerts for more than just our demo alert definition then you could choose which types of alerts it should cover.

Alternatively we could base the notification trigger around the impact of the alert. This would mean is the scope of our alert (the cluster) being impacted in an area of Health, Risk or Efficiency. Our alert definition was classed with an impact of “Health” so if we were going to use this trigger we would select “Health” here.
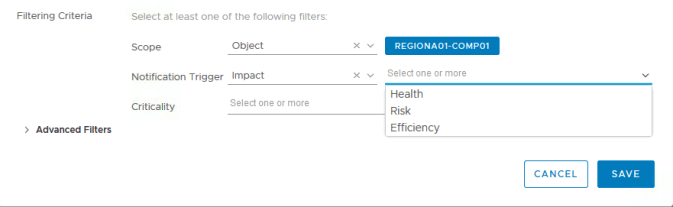
For the purposes of this demo our trigger is going to “Alert Definition”. This means we can manually select the alert definition that will trigger the notification. Note that you can only select one so if this rule is for more than one alert you would need to choose another type of trigger.
The criticality provides the user the ability to set which of the alert conditions requires the email notification. Our alert definition has 3 conditions (warning, immediate and critical) however we might not want an email to be sent for all of those. In this example we are only going to send an email for immediate and critical.
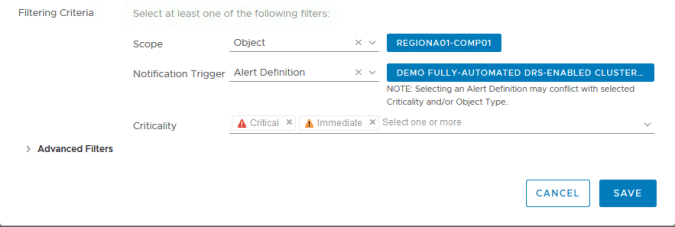
Further filters can be added to only send emails if the alert is new or open but not assigned etc. using the advanced filters option.
Once submitted the alert will show in the notifications pane.


Pingback: vRealize Operations – Security Compliance | vnuggets