The last couple of work days have been taken up by doing some knowledge transfer to one of my customers, specifically for the topic of custom dashboard creation. One of the subjects of discussion that has come up several times is around instanced metrics so today I thought I would put together something to help explain what they are and how you can use them.
What Are They?
Normal object metrics exist on all objects of the same type no matter what their configuration (assuming all objects concerned are covered by the same policy settings). For example, VM “ABC” will have a CPU Usage % metric as will VM “DEF”. As all of the same object types have the same normal metrics you can build a view or dashboard to show the information and be confident that all of the relevant objects will show data.
There are some parts of an objects configuration that differ for each instance of that object. For example, VM “ABC” might have one vCPU where as VM “DEF” might have 2 vCPUs. Although each machine will have the same metrics that summarise the whole objects performance/configuration for a given area (e.g. CPU Usage MHz) each CPU within a VMs configuration will also have its own metrics.
For example, below are CPU metrics for 2 machines. The first machine has 1 vCPU and the other has 2 vCPUs. Both have the same summary metrics but each also has a set of metrics that represent each CPU.
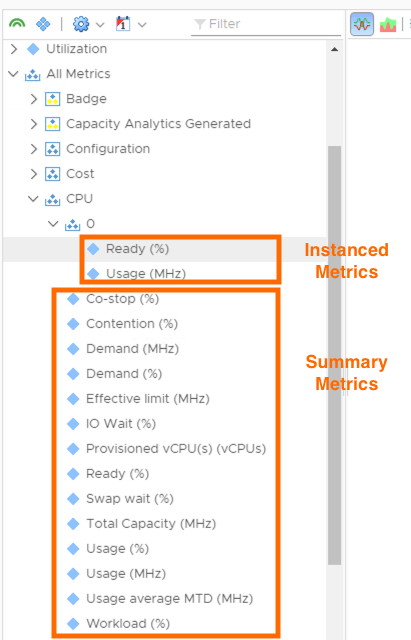
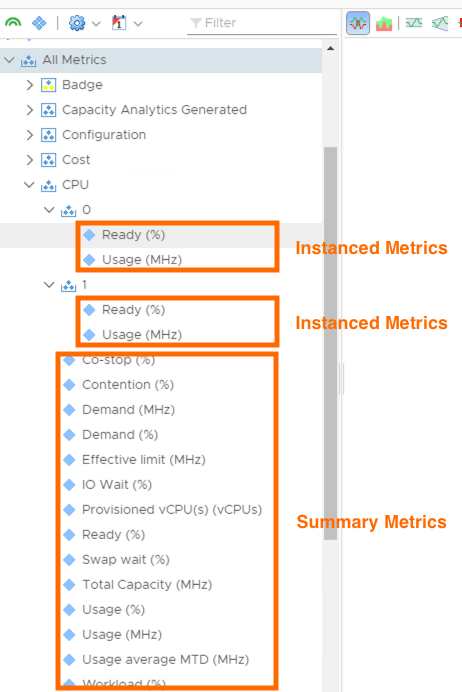
The normal metrics summarise a given resource area across all instances of that area (i.e. CPU Usage MHz shows the total CPU Usage in MHz for all CPUs on the VM). If you want to show data for a specific vCPU within a VM then you need to reference the correct CPU instance for that machine.
Instanced Metrics in Dashboards and Views
Leveraging instanced metrics in a common dashboard/view can be problematic in some scenarios. If you want to build a table of data for CPU utilization (in thsi case using a view) and all of the VMs that could be displayed in the table have a wide range of CPU configurations then this could lead to a very wide table that is not relevant for some of the machines in question.
In this example the majority of the machines in my environment have between 1 and 4 vCPUs however a few have 8. This leads to table that has null entries in the columns for vCPUs 5-7. As my table has to handle all possibilities I cannot remove the metrics for vCPU 5-7 as at some point in the future i might create a 6 vCPU machine. Equally, if I ever build a machine that is beyond 8 vCPUs then I would need to adjust my view to accomodate this increased configuration.
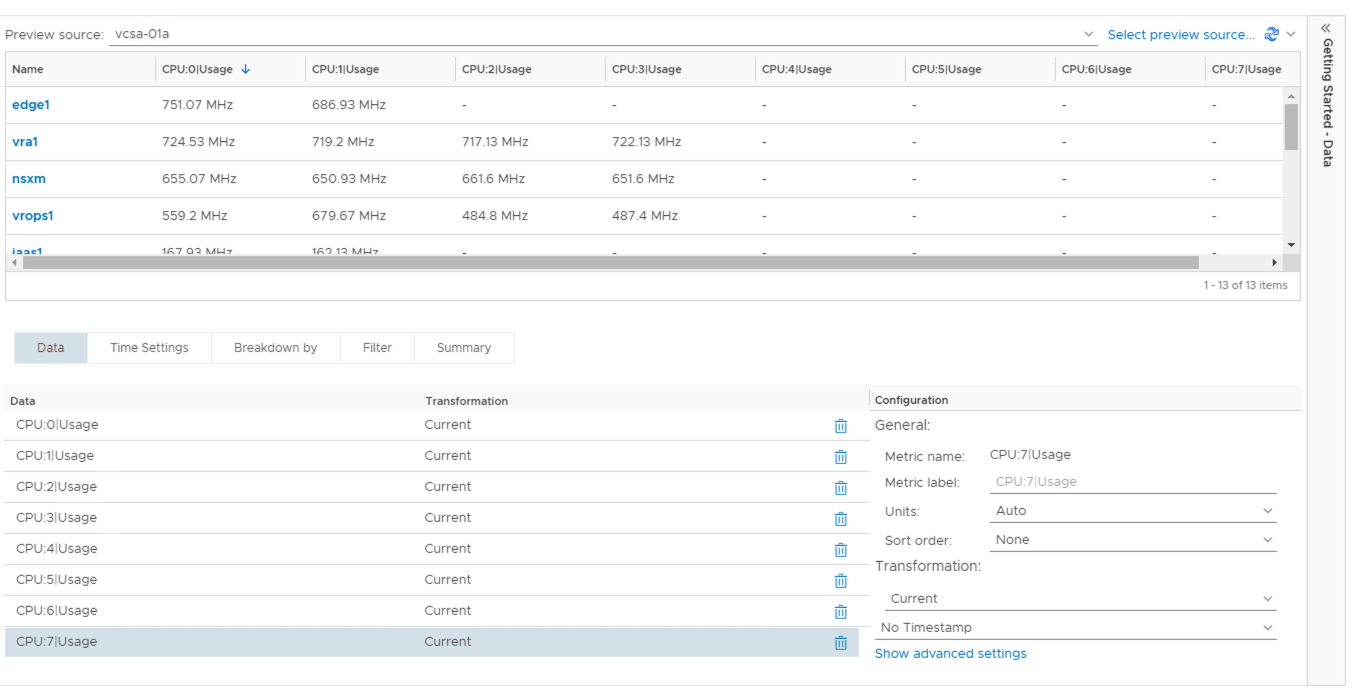
This type of table is static in nature and requires maintaining in order to show all of the correct data.
Another way to use instanced metrics within the view is to use the “Breakdown by” feature. This enables you to select an instanced metric when building the view and tell vROps to represent each instance of that metric as a new line item within the view table. In this case we are asking vROps to show each vCPU as a separate line item.
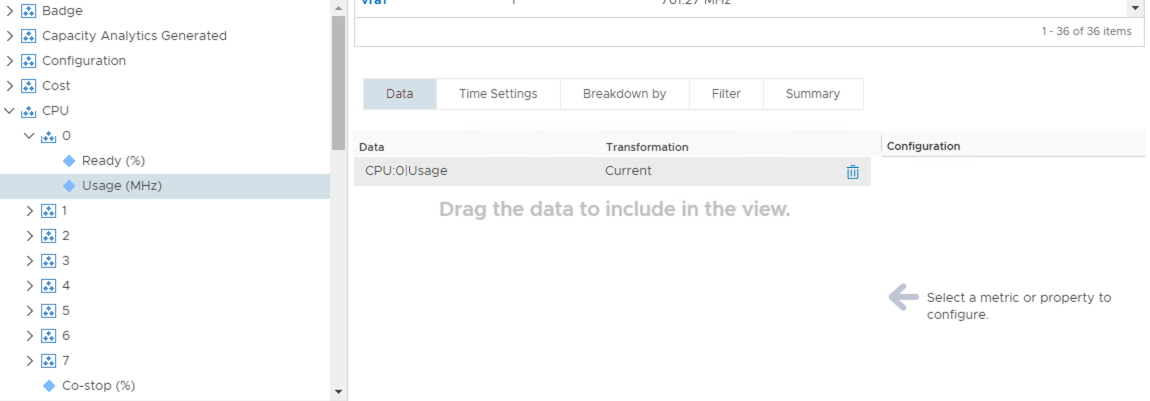
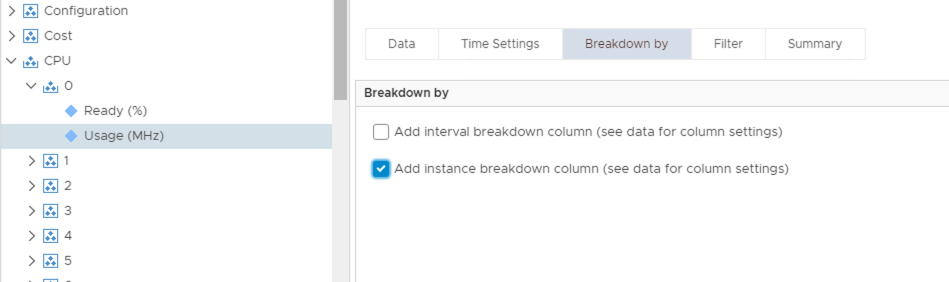
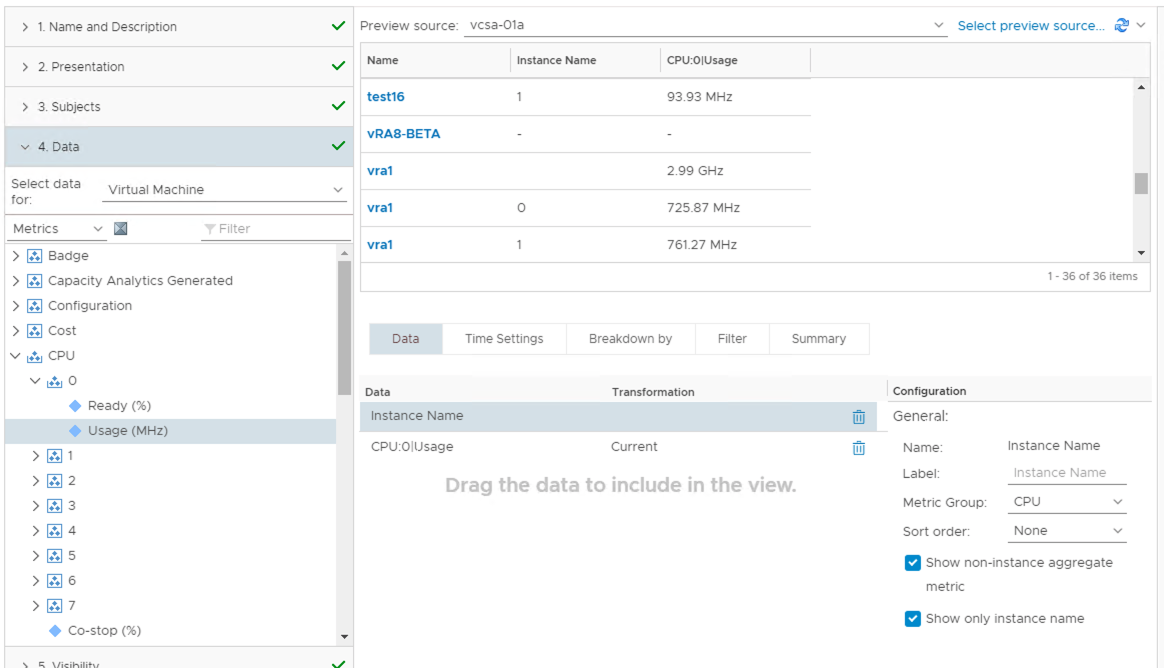
The table is now dynamic in nature and will automatically adapt to varying configurations. A summary line is also displayed for each object type in question, in this case a VM summary that shows the total of all the CPU metrics being used. This can be removed by un-selecting the “Show non-instance aggregate metric” checkbox.
The downside to using this method is that you can no longer represent an object as a whole on a single line. If this doesn’t meet your needs then using a static table is the only option available to you.
Hopefully this has given some insight into instanced metrics.
