Overview
In part 5 of this series I covered access control for PKS. In this article I am going to step down a level and see how I can control and grant access into individual PKS clusters for users/groups which are not already defined as PKS admins/cluster admins using a combination of PKS CLI and Kubectl.
Other article in this series can be found via the following links.
- Part 1 Overview
- Part 2 Ops Manager and Bosh
- Part 3 NSX-T Prep
- Part 4 Installing PKS
- Part 5 Granting PKS Access
- Part 6 Cluster Operations
- Part 7 Cluster Access
- Part 8 Harbor Registry
Roles
Allowing access to a PKS Cluster (i.e. Kubernetes) is done unsurprisingly via “kubectl”. This is the command line interface for running commands against a Kubernetes (PKS) cluster which in this case I will use to define a “role”.
A Kubernetes role contains information that describes a set of permissions and what Kubernetes resources those permissions relate to. So before I get into LDAP and users/groups I need to define a role I want my users to have. In this case I’m going to create a sudo admin role which has most permissions required to deploy/manage/delete services/deployments/pods on my cluster.
The role is defined using a yaml file which needs to contain the following information. Note that only the bold items need me to make decisions for their values.
- Type of role (is it just for one namespace or for the entire cluster)
- API to use
- Name of the role
- Namespace to target (if not a cluster wide role)
- API groups (the API sections you want a user/group to be able to use)
- Resources (the Kubernetes resource types that should be available)
- Verbs (what type of operations should be allowed)
Here is a yaml template for creating a Kubernetes role.
kind: INSERT_ROLE_TYPE
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: INSERT_ROLE_NAME
namespace: INSERT_NAMESPACE_NAMES(S)
rules:
- apiGroups: [INSERT API GROUP(S)]
resources: [INSERT RESOURCE(S)]
verbs: [INSERT VERB(S)]For my cluster I am going to create a role for the entire cluster rather than just individual namespaces. This means my role type is “ClusterRole” (for individual namespaces it would be “Role”).
Next I need a name for my role. I am going to call it “CORP-Cluster-Admin”. As I am creating a ClusterRole I do not need to include the name of a namespace so that can be omitted.
The API Groups is where things starts to get interesting. This basically means which sections of the Kubernetes API do I want to open up to the users who will be linked to this role. Various sub-branches of the Kubernetes API allow different types of resources to be created, modified, deleted etc. To help me make a decision I can list all of the Kubernetes resource types and see the API Groups that each resource is linked to.
Note to execute this command you need to be authenticated into the cluster (see part 6 of this series).

From the above list I am going to use “apps” (covers all API operations relating to deployments, pods, replica sets etc.) and “networking.k8.io” (covers creating Ingress services like load balancing). In addition to that I also want my users to be able to see pods, namespaces, nodes etc. which are all part of the default API Group.
My list of API Groups will be [“”,”apps”, “networking.k8s.io”]. Note that the default group is specified as just 2 double quote marks.
Now I can decide the resource types I want this role to cover. I can use the same out list above to see the individual resources I want to expose. I am going to choose [“deployments”, “pods”, “services”, “endpoints”, “namespaces”].
The last part is to determine what types of operations I want this role to allow my users to perform on my resources. The list of Kubernetes verbs can be found here and they align to the standard HTTP verbs (“GET”, “POST”, “DELETE”, “PUT”, “PATCH”) in a one to many relationship as follows.
| HTTP Verb | Kubernetes Verb(s) |
| GET/HEAD | get, list or watch |
| POST | create |
| PUT | update |
| PATCH | patch |
| DELETE | delete, deletecollection |
If you look at the Kubernetes API (version 1.16 referenced) each API call will use a standard REST HTTP verb. So to get a deployment uses a “GET” REST request but that could be a Kubernetes “get” or “list” verb depending on whether you want to return a single deployment or multiple deployments.
I am going to use a verb list that looks like this [“get”, “watch”, “list”, “create”, “update”, “patch”, “delete”. “deletecollection”]. In other words I am giving users of this role the full range of available operations on the resource types the role covers.
The final yaml file looks like this:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: CORP-Cluster-Admin
rules:
- apiGroups: ["", "apps", "networking.k8s.io"]
resources: ["deployments", "pods", "services", "endpoints", "namespaces"]
verbs: ["get", "watch", "list", "create", "update", "patch", "delete", "deletecollection"]Bindings
The binding is the second part of granting access. Once I have a role I then need to bind users to that role so that Kubernetes knows which users can login and what permissions that should have when they login. This binding is also created by populating a yaml file. A template file looks like this.
kind: <INSERT_BINDING_TYPE>
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: <INSERT_NAME_OF_BINDING>
subjects:
- kind: <INSERT_USER_OR_GROUP>
name: <INSERT_NAME_OF_USER_OR_GROUP>
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: <INSERT_TYPE_OF_ROLE>
name: <INSERT_NAME_OF_ROLE_CREATED_IN_ROLE_YAML>
apiGroup: rbac.authorization.k8s.ioThe binding type should relate to the role defined previously, whether it is for a Role or ClusterRole. The two types are shown below.
- Role = RoleBinding
- ClusterRole = ClusterRoleBinding
The name of my binding will be “Corp-Admin-Role-Cluster-Binding“.
For this test I am going to be mapping an individual user so that subject Kind will be “User” and the name of the user is “k8s-cluster-admin”. However, the name of the user/group you add must be prefixed with the setting used for the PKS UAA configuration which is “oidc” by default.
This means that my binding needs to have “oidc:k8s-cluster-admin” as the user.
The last part of the definition relates to the role I am linking the user to which needs the type of role (“ClusterRole” in my case) and the name of the role (“Corp-Cluster-Admin“).
The final binding yaml file looks as follows:
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: Corp-Admin-Role-Cluster-Binding
subjects:
- kind: User
name: oidc:k8s-cluster-admin
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: CORP-Cluster-Admin
apiGroup: rbac.authorization.k8s.ioApplying Roles and Bindings
Now that I have role and binding yaml files they need to be applied to my cluster. To do this I am going to get the admin credentials via PKS CLI for the cluster which will give me admin access to Kubernetes for kubectl to use.
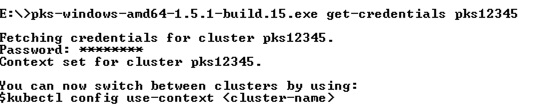
Now that I have admin access to the cluster I can use it to create/apply the yaml files to the cluster.

Once applied I can then use the PKS CLI to fetch an auth token for my “k8s-cluster-admin” user, populating my kubeconfig file (this will overwrite the admin creds I previously retrieved).

Once authentication succeeds I can now perform Kubernetes API calls to the cluster using kubectl. Here I am trying to list all the namespaces and pods on my cluster however neither is working. I had 2 issues here, the first was that I had a rogue space in the default API Group and the second was that I hadn’t called out “namespaces” in my list of resources (the yaml files above are both correct).

To fix my mistakes I first updated my role definition yaml file and then re-authenticated to my cluster as admin. This time I executed an “apply” rather than “create” as the role already existed, it just need updating.

After this update I was able to re-authenticate with my k8s-cluster-admin user and perform the operations I was expecting.

This is just a very small view of how permissions can be used on Kubernetes clusters created by PKS but hopefully it gets you started.

Pingback: PKS – Getting Started Part 6 Cluster Operations | vnuggets
Pingback: PKS – Getting Started Part 5 Granting PKS Access | vnuggets
Pingback: PKS – Getting Started Part 4 Installing PKS | vnuggets
Pingback: PKS – Getting Started Part 3 NSX-T Prep | vnuggets
Pingback: PKS – Getting Started Part 2 Ops Manager and BOSH | vnuggets
Pingback: PKS – Getting Started Part 1 Overview | vnuggets
Pingback: PKS – Getting Started Part 8 Harbor Registry | vnuggets